Medical Temporal Constraints
Large Language Models can Extraction Medical Temporal Constraints from Drug Usage Guidelines
What Are Medical Temporal Constraints?
Medications usually come with specific instructions about when and how to take them. These instructions, which we call medical temporal constraints (MTCs), are very important for the treatment to work effectively and to ensure patient safety. If patients don’t follow these guidelines, it can lead to health problems and higher healthcare costs. These MTCs are usually found in drug usage guidelines (DUGs), which are included in materials given to patients by doctors, and in other patient-centric education materials like those found on sites like WebMD. In this work, we created a structure to represent these MTCs as they appear in free-formatted patient health texts, and we explore the automatic extraction of these structured outputs using large language models (LLMs). This work can help outline safe patterns of activity for patients and improve healthcare applications that are focused on patient needs.

What is In-Context Learning?
In-context learning (ICL) is a recent approach in language modeling where a LLM is given a task to perform after being provided with a prompt and several examples. In-context learning is different from traditional machine learning because the weights of the LLM are frozen (i.e. no backpropogation occurs); all of the task-specific knowledge is “learned” in context through the prompt and given examples. ICL is like teaching a model to perform a task by showing it only a few examples, and since the model has been trained to do a bunch of other language tasks it can reliably perform your specialized task as well. There has been a bunch of interesting investigation into why ICL works. However, in this work we focus only on how well ICL works for our patient-centric task. In related work, ICL has been found to be effective in extracting structured information from text, including scientific and medical structured information.
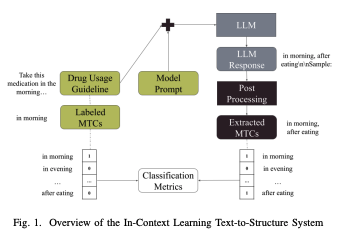
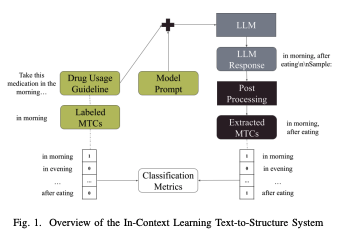
We used ICL with the GPT-3 model from OpenAI to extract MTCs from unstructured DUGs. We chose GPT-3 because it has been shown to be effective in extracting this type of information using ICL strategies, especially when the dataset is relatively small and training a new model is infeasible.
We designed three types of prompts to guide the model in extracting MTCs from unstructured text data. The first is a simple prompt that serves as a baseline for ICL. The second is a guided prompt, which is longer and includes elements of the labeling guide given to human annotators. The third is a specialized prompt, which is customized for each type of MTC and includes a basic description and a heuristic for formatting the MTC correctly.
What Did We Learn?
The specialized ICL prompt achieved an average F1 score of 0.62 across all datasets, demonstrating its relative effectiveness in extracting and normalizing MTCs from DUGs. We found 2 main sources of error in the GPT-3 output, hallucination and nonvalidity, which we describe below.
Hallucinations are the most common error type, accounting for 43% of all labeled errors. Hallucination occurs when the model outputs an MTC or a list of MTCs that are valid but not found in the text sample (i.e. the model “hallucinates” information that was never seen in the sample context). This error type is particularly common in consistency and time-of-day MTCs.
Nonvalidity is another common error, accounting for 15% of the errors. This happens when the model output cannot be parsed according to the context-free grammar (CFG) after minimal post-processing.
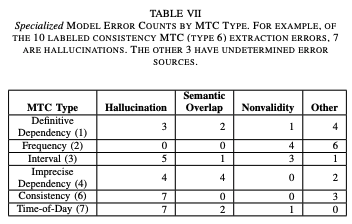
These errors affect the model’s performance in extracting MTCs, with hallucinations being a primary reason for poor performance. Reducing these errors is an active area of research that could lead to better results in MTC extraction tasks.
What’s Next?
Our research has shown that it is possible to computationally represent MTCs in DUGs using a CFG-based model and an ICL solution. This approach can help improve patient adherence to medication guidelines and ultimately lead to better health outcomes. However, there is still room for improvement, particularly in the extraction and normalization of certain types of MTCs. Future research could focus on refining the ICL model and exploring other methods for MTC extraction.